Todays question is: Can we tell when records have been deleted from an SQLite database?
TL;DR – We can provide some time and date information in very particular circumstances using the WAL log file. It can be very time consuming!
Quick warning – This article will assume some knowledge of SQLite databases. I will probably do some further posts on the fundamentals of SQLite databases as I think they are essential for any Digital Investigator. I will be doing posts on SQLite work in general and as I write them I will try and update this one with links to the other information.
Edit (20/11/2020) : I’ve now written the post on SQLite fundamentals – can be seen here
Background
This came up as part of an investigation where a number of text messages were deleted from a mobile phone device and it was necessary to attribute time and date information to the deletion. The records were some of the last ones on the device and it had been turned off/very little usage after the deletion.
The work I completed for this case obviously can’t be shared, and it was harder work to create test data for an IOS device for SMS/iMessage database, so throughout this I will be using test data from the Mozilla Firefox browser. The same principles apply to the original use case, though the technical details are slightly different.
Tools used throughout this post:
- X-Ways Forensics – can use other forensic tools and work around, but template files require X-Ways.
- SQLite Viewer – SQLiteSpy 1.9.14 (x64) – Download from here
- XT_SQLiteRecordDecoder 0.3 – One of my creations, available here
- Some X-Ways Templates – Available on downloads page here
Data used in examples:
- Firefox WAL Data.vhd – Available here
Starting point
A quick examination of the SQLite database, that the records in question were located in, shows that the records are currently deleted in the database when the SQLite database and associated files (WAL and SHM files) were extracted from the exhibit. However, if just the SQLite database was extracted and viewed, the records were still showing as live in the database.
So why is this happening? Well the SQLite database system uses journaling to keep the integrity of a database if something unexpected happens (power outage to device etc.). There are two methods in use; Rollback Journal and Write Ahead Logs (WAL).
Rollback journals include information to restore a database back to its original state if a transaction fails, write ahead logs contain updates to the database that are then committed to the main database at a later time. In this case, the database that we were examining uses a Write Ahead Log, so Rollback journals will not be discussed further here.
The important information, that allows use to deduce dates and times for record deletions in this case, is that records in the SQLite databases have dates and times as part of the records. In the case of the SMS/iMessage database this would be the sent/received times and with the Firefox database we have last visited/visited times and dates. Without this information we would probably not be able to determine when the records were deleted.
Overview of WAL files
In order to understand how we are going to use these files to associate time and date information, we need to know some important information on how the WAL file works. The WAL file is always in the same folder as the database and has the same name but with “-wal” appended to it.
The SQLite database itself is made up of a series of pages that contain the records, and associated information, that are stored in the database. Notably pages in SQLite start from 1 rather than 0.
The WAL file consists of a header followed by a number of “frames”. Each frame contains a frame header and a page worth of data from the database with the updated contents. The same page can appear multiple times in the same WAL file; each time the page needs to be updated the latest version is found (either in WAL or database file) and then changes made and written to end of the WAL file.
The header of the WAL file has 2 Salt values as does each frame. For a frame to be considered valid, the 2 salts in the frame header must match the 2 in the WAL header.
Below is a very simple of sequence of update events with a diagram.
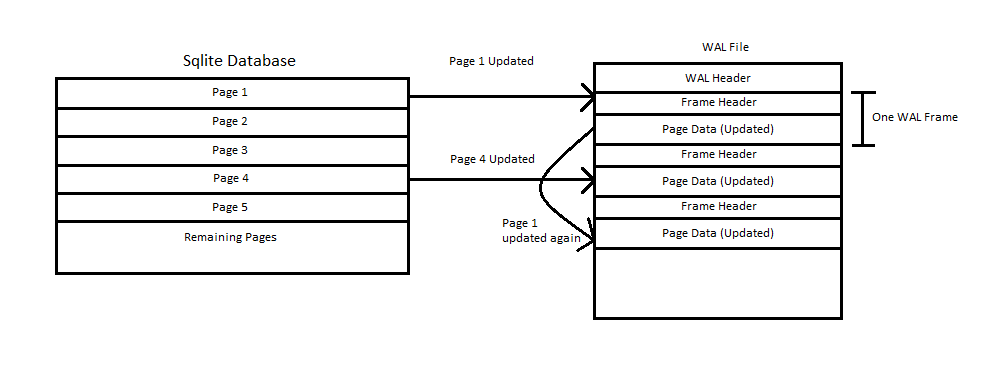
The diagram above shows 3 update operations to the main SQLite database. The first is an update to page 1 and prior to this, the WAL log can be considered empty. As the page being updated does not already exist within the WAL file, a copy is made to the WAL file and the updates to the page are made in the copy of the page. The data within the SQLite database remains unchanged.
Next an update is made to page 4. Again this page does not exist already within the WAL file and so a copy of the page is made in the WAL file and updates made to the copy of the page.
Lastly, page 1 is updated again. As the page already exists within the WAL file, a copy is made of the earlier version of page 1 within the WAL file and this is moved to a new frame at the end of the WAL file. The new updates are then made to the later copy of the page 1 data.
At the end of this process, we have 3 versions of Page 1; One within the main database, one in the first frame of the WAL file and one within the 3rd frame of the WAL file. We also have 2 copies of page 4 in a similar manner. Each of the copies of the pages are different and the may be records that exist in the Page 1 in the first WAL frame that do not exist in the copy in the 3rd WAL frame.
There is a lot more to WAL files than described here, but this should be sufficient information for us to review the data.
Test data and setup
As I’ve created test data for this particular post, I’ll detail each of the actions taken, including the time, so that we can use it to compare against our results. All actions were taken on the 24/09/2020. Prior to the actions below, a new Windows 10 was set up and Firefox was installed. Once installed, all history was deleted from the database. Throughout the process, copies of the databases we created and these are labelled Point 1-4. When the copies were made is also listed below.
| Time | Action |
| – | Initial copy of databases taken |
| 0937 | Accessed BBC news website – |
| 0938 | Accessed BBC news article |
| 0938 | Moved to sports section of BBC News |
| – | Took a copy of Database and WAL files (Point 1) |
| 0939 | Deleted access to BBC news article |
| – | Took a copy of Database and WAL files (Point 2) |
| 0940 | Accessed URL of misspelt Dilbert website – |
| 0940 | Visited Dilbert Website – |
| 0940 | Accessed About section of Dilbert Website |
| – | Took a copy of Database and WAL files (Point 3) |
| – | Closed browser |
| – | Took a copy of Database (Point 4) |
As you can see, this is a very simple timeline of events; accessed a few webpages, deleted one and then accessed a couple more.
So in this instance, we know that the deletion was done at 0939. In this case we have multiple copies of the database as we go through the activity, in reality we would only have the one at most. This is mostly to illustrate how the logs are used but the technique is still possible with just the 1 set of files at Point 3.
Viewing the test data
The database files have been included in Virtual hard disk, so it can be mounted on any Windows Machine and set to read only. The Virtual hard disk can be attached using the Disk Management service, available from the Quick Link menu (Win key+X). It can also be accessed natively by a lot of forensic tools, including X-Ways Forensics.
On the disk, there are 4 folders, the initial SQLite database with no WAL file, Point 1-3 folders with a WAL/SHM file each and a Point 4 folder with no WAL file.
The templates that are shown at the top of this post can be used to quickly decode the hex data if using X-Ways/Winhex (with licence). Otherwise the data can be examined manually in other tools. All the offsets are shown throughout this post.
Before we start examining the files, all of the structures used in SQLite are Big-Endian, make sure that whatever tool you are using is set up to interpret Big-Endian data. I will be using X-Ways Forensics throughout and other tools may display slightly differently.
WAL Structure
So firstly we need to look at the structure of the WAL file (tables taken from SQLite 3 website):
WAL Header Format
| Offset | Size | Description |
| 0 | 4 | Magic number. 0x377f0682 or 0x377f0683 |
| 4 | 4 | File format version. Currently 3007000. |
| 8 | 4 | Database page size. Example: 1024 |
| 12 | 4 | Checkpoint sequence number |
| 16 | 4 | Salt-1: random integer incremented with each checkpoint |
| 20 | 4 | Salt-2: a different random number for each checkpoint |
| 24 | 4 | Checksum-1: First part of a checksum on the first 24 bytes of header |
| 28 | 4 | Checksum-2: Second part of the checksum on the first 24 bytes of header |
Important information that we require from here:
- Database page size – Then we know how much data is stored in frame
- Salt 1 & 2 – We can use these to check for valid frames.
To be thorough, we should also use the Checksums to check the integrity of the frames, but as that requires computation, rather than simple matching, we will just use the salts.
Immediately after the WAL header (offset 32/0x20) we have the first frame which starts with a frame header:
WAL Frame Header Format
| Offset | Size | Description |
| 0 | 4 | Page number |
| 4 | 4 | For commit records, the size of the database file in pages after the commit. For all other records, zero. |
| 8 | 4 | Salt-1 copied from the WAL header |
| 12 | 4 | Salt-2 copied from the WAL header |
| 16 | 4 | Checksum-1: Cumulative checksum up through and including this page |
| 20 | 4 | Checksum-2: Second half of the cumulative checksum. |
So we know that the size of the frame header to 24 bytes and we have the page size from the WAL header format, adding these together gives us the size of each Frame.
If we apply the template to the first 24 bytes of any of the WAL files (they should all be the same) we get:

This provides us with some useful information, including the SALT 1 & 2 values that will be required to check each frame is valid. It has also provided us with that page size, which is required to figure out the correct frame size, as 32,768 bytes.
Firefox History
With this information in hand, we need to apply it to our Firefox SQLite database and associated files. If you are not familiar with how Firefox stores history in the places.sqlite database, there are many good articles out there that cover it in far more detail than I will. However there are 2 tables in the database that we are going to focus on; moz_places and moz_historyvisits.
The moz_places table contains the URL and other information relating to a specific webpage. The moz_historyvisits contains information relating to when an entry in the moz_places table has been visited, including time/date and how the site was accessed. When the last reference in the moz_historyvisits is deleted for a particular entry in the moz_places table, the corresponding entry in moz_places should also be deleted. As there is only on reference to the deleted record, so we can either examine for changes to the moz_places table or the moz_historyvisits table

Examination of the WAL file
If we start on the first frame of the “Point 1 “WAL file (offset 32/0x20) and apply the template we get the following information:

This tells us that this frame relates to page 2 of the database. This doesn’t immediately help us, as we don’t know if that has any relation to the two tables we are interested in!. The SALT 1 and 2 values match those shown in the header, so we are happy that the frame itself is valid.
So how do we check for pages relating to a particular table? Well for this we need to view the hidden table in the places.sqlite database, the SQLITE_MASTER table. This table exists in all SQLite databases and can be accessed using the standard select query. So running the command “SELECT * FROM SQLITE_MASTER” on the database gives us the following results:

So we can see 1 entry for moz_places and one for moz_historyvisits. The most useful information is the ‘rootpage’ field (4th column) and this gives us the starting page for this database. In this case the root page for moz_places is 4 and moz_historyvisits is 12.
If the tables contained more records, then the data would be split into multiple pages and the data in the root page would show us where the other data was stored. In this case, with a relatively small amount of data, the entire data for that table is stored in the root page. If this were not the case, we would have to identify all the pages associated with the table and examine for all of them.
So one way to find the data for each page would be to look at the header of the first frame header (offset 32/0x20) check if it’s for a page we are interested in. If so review the data, if not jump to the next frame header by jumping (Frame Header Size + Page Size) bytes. This is quite time consuming and there can be a large number of pages per WAL, even in our small example.
The solution is to take advantage of some of the nice keyword search functionality in X-Ways Forensics. It has the option to run searches at set offsets rather than every byte using the “Cond: Offset mod”. So if we search for the hex “00 00 00 04”, Big Endian value 4, at Offset 32 every 32792 (header size + page size) bytes, we will find any frame header that relates to page 4. See below for the options as seen in X-Ways. We know the first header is at 32 bytes due to the WAL header taking up those first 32 bytes. Then we want to jump a full frame and check offset 32 (next frame header) for the value and so on and so forth. Please note that this setting will stay on next time you run a search and I accept no blame for you not finding search hits in your next job because you left this conditional offset on!

If we run this on the “Point 1” database, we would see the following offsets for hits:

If we run this on the “Point 2” database, we would see the following offsets for hits:

As we can see, there is an additional entry at 1082168 that exists in the “Point 2” database but not the “Point 1” database. Also notice that there are references to this page after this offset; will look at these later.
If we go to file offset 1016584 and look at the page data there, using the X-Ways template, we see:
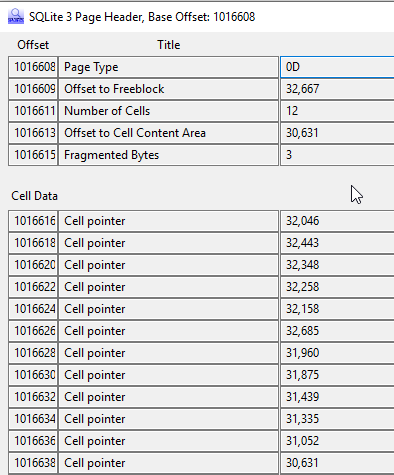
So we have 12 live records in this page. Now if we do the same for the page data stored in the frame starting at 1082168 we get:
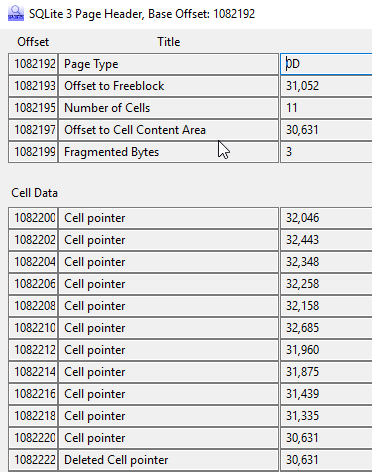
So here we can see that the cell pointer at page offset 31,052 has been deleted and the pointer to 30,631 has been moved to the slot that contained the offset. Notice the first deleted cell pointer is also 30,631 as the address is not cleared when it moves.
So going to back to the frame starting at file offset 1016584, if we jump 31,052 bytes from the start of the page header, we get the following hex data:
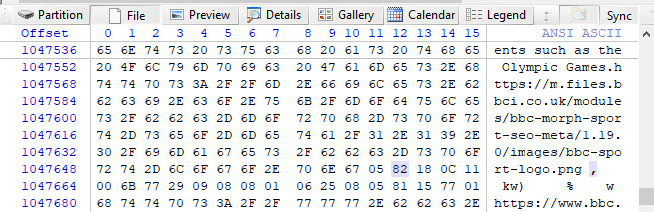
I’ve highlighted the 1st byte of the data. From here we could decode the SQLite record and view the data. I’m not going to cover how to do this manually in this blog post, it’s almost a post in its own right, but I am going to introduce an X-Tension that I have created to make this process easier.
The XT_SQLiteRecordDecoder X-Tension (link at top of this post) requires you to highlight the start of the SQLite record and it will then decode the rest and highlight the entire record. In needs to be used from the disk/partition view in X-Ways rather than the file view. So if you place your cursor on the first byte of the record and press the partition button on the top left of the hex window you should be taken to partition offset 34,2087,875. Highlight the “82 18” hex values by dragging across the data window. Should look like this:

Now press the “Run X-Tensions” button on the menu at the top of the X-Ways interface:

This will give you the menu to run the X-Tension:
On your first time running the X-Tension, you will have to provide X-Ways with the location and this can be done by pressing the “+” button on the bottom middle of the dialog box. Once the X-Tension is highlighted, press OK and the following should be displayed in the output window:
[XT] Record ID:12 Record Length:280 Header Length:17
[XT] Record Data:"12","https://www.bbc.co.uk/news/av/business-54268400","Brexit: Why is it so hard to reach a deal? - BBC News","ku.oc.cbb.www.",1,0,0,"100","1600936685597000","KLmlJJvjjSPQ",0,"47356514151165","Time is running out to reach a Brexit deal - what are the obstacles?","https://ichef.bbci.co.uk/images/ic/400xn/p08sbh6q.jpg","5"Given that we know the structure of the database, we can match each of these values back to a field. The whole record should also be highlighted in the hex window:

The value “1600936685597000” is the last visit time and we use this as the time the record was entered into the database. This value is a Firefox timestamp, which is a Unix timestamp in milliseconds rather than seconds. Dividing it by 1,000,000 gives us a Unix timestamp and this one translates to 24/09/2020 at 08:38:05 UTC.
So we now have our time for the record being created in the database.
In order to locate our next timestamp that we can use, we need to look at the point 3 database. If you run the same search for WAL headers relating to Page 4, you should get the following list:

So the frame at file offset 1082168 was the last frame we examined in the Point 2 WAL file, so the next change to the page would be located at file offset 1574048. You may have noticed that some of the offsets after this offset are different to the previous databases. This is due to previous WAL records, which have been committed to the database, being overwritten with new WAL records. I’ll cover this a little more at the end of this post.
Now if we examine the frame at offset 1574048 we can see that the number of cells is back up to 12 and that the last offset is different. The new data has taken some of the space previously occupied by our deleted record.
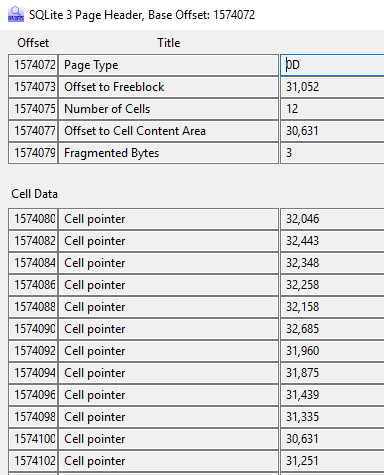
If we go to page offset 31,251 we can see the record for the (misspelt) www.dilbrt.com

Decoding this record using the XT_SQLiteRecordDecoder X-Tension gives us the following information:
[XT] Record ID:14 Record Length:82 Header Length:16
[XT] Record Data:"14","http://www.dilbrt.com/","<NULL>","moc.trblid.www.",1,1,1,"2000","1600936808068000","8dLkpvxIP9tC",0,"125510922083568","<NULL>","<NULL>","6",1600936808068000 again is a Firefox timestamp that translates to 24/09/2020 at 08:40:08.
So now we know when the record was added to the database and when the next record was added. So logically we can deduce that the deletion has to have taken place between 08:38:05 and 08:40:08 on 24/09/2020 (UTC).
We could have proved this in a similar manner using the moz_historyvisits table and matching the visits record to the moz_places url. Potentially we could have narrowed this down further using the record relating to the BBC sports section, which is recorded as being last accessed at 08:30:30 UTC on the same day, using the exact same techniques.
I hope this has been helpful in showing a practical example of how time lining SQLite records using the WAL file is possible (if quite time consuming to do manually!).
P.s: Hits from later in the WAL file
So earlier we discussed that there were hits for the page number after the latest record that we were interested in. So to explain that, we shall have a look at the WAL frame header located at offset 1934760 on the “Point 2” WAL database and compare it the one from offset 1016584 of the same database.


See how the SALT 1 and 2 values don’t match, this is because the WAL frames are from before the last checkpoint operation on the database, where the WAL data is integrated back into the database. The SQLite3 File format specifies that the WAL salt-1 value is incremented by 1 and the salt-2 value is randomized, which is why the salt-1 value in the header at offset 1934760 is 1 larger that value in the header at offset 1016584.

One thought on “Timelining using SQLite Write Ahead Logs”